
Кластеризация
Кластеризация медицинских данных с помощью нейросетей
Симахин В.А., Кашинцев А.В.
Курганский государственный университет, г. Курган
1. Введение
В последние десятилетия интенсивно развивается новая прикладная область математики, специализирующаяся на искусственных нейронных сетях (НС). НС используются при автоматизации процессов распознавания образов, адаптивном управлении, аппроксимации функционалов, прогнозировании, создании экспертных систем, организации ассоциативной памяти. Медицина – это одна из областей, где НС часто и успешно применяются.
2. Описание предметной области
В биохимической лаборатории гастроэнтерологического отделения Курганской областной больницы в течении нескольких лет проводилось исследование динамики изменения характеристик желудочного сока у пациентов в процессе пищеварения. Исследования проводились следующим образом. У пациента измерялась концентрация желчных кислот. После этого в желудок вводился зонд, с помощью которого через каждые 15 минут измерялись объём желудочного сока и его кислотность. Всего проводилось 8 замеров. После 4 замера пациенту вводили стимулятор (гистамин). Целью этих исследований было определение зависимости между измеряемыми показателями и диагнозом пациента, а также выделение групп пациентов с характерными значениями данных показателей.
3. Постановка задачи
Исходные данные представляют собой набор точек в 17-мерном пространстве. Каждой такой точке сопоставлен класс (диагноз), к которому она принадлежит. Нашей задачей является разбиение множества точек на кластеры и сопоставление полученного результата с распределением точек по классам. Для кластер-анализа используется нейросеть Кохонена.
4. Описание нейросетевой модели Кохонена
Карты самоорганизации Кохонена (SOM: Self-Organizing Map ) — нейросетевая архитектура для неконтролируемого обучения. Она была предложена Кохоненом в 1982 г. и с успехом использована в самых различных приложениях.
В мозге нейроны располагаются в определенном порядке так, что некоторые внешние физические воздействия вызывают ответную реакцию нейронов из определенной области мозга. Например, в той части мозга, которая отвечает за восприятие звуковых сигналов, нейроны группируются в соответствии с частотами входного сигнала, на которых они резонируют. Хотя строение мозга в значительной степени предопределяется генетически,
отдельные структуры мозга формируются в процессе самоорганизации. Алгоритм Кохонена в некоторой степени напоминает процессы, происходящие в мозге.
SOM имеет всего два слоя: входной и выходной, составленный из радиальных элементов (выходной слой называют также слоем топологической карты). Количество нейронов во входном слое равно размерности данных в обучающей выборке. Элементы топологической карты располагаются в некотором пространстве — как правило, двумерном. Число нейронов в нём определяется эвристически. Каждый нейрон входного слоя связан с каждым нейроном топологического слоя. Веса связей, идущих к нейрону топологического слоя, определяют центр кластера, соответствующего этому нейрону.
Для определения класса, к которому принадлежит вектор, его координаты подаются на соответствующие входные нейроны. После этого вычисляется расстояние между входным вектором и векторами весов связей для каждого нейрона выходного слоя, которые преобразуют полученную величину с помощью функции Гаусса. Таким образом, нейрон, ближайший к предъявленному вектору, имеет наибольшее значение на выходе, что и определяет класс, к которому относится вектор.
Процедура обучения SOM состоит из следующих шагов:
- Инициализация весовых коэффициентов:
Весам связей присваиваются случайные значения, равномерно распределённые в пространстве входных векторов.
- Нахождение ближайшего нейрона.
На каждом шаге обучения случайно выбирается один вектор X из набора входных данных, и вычисляется его расстояние до векторов весов выходных нейронов. Обычно применяется евклидово расстояние. Выбирается ближайший нейрон C.
- Модификация весовых коэффициентов.
Вектора весов нейрона C и его топологических соседей смещаются ближе к входному вектору. Веса модифицируются по следующей формуле:
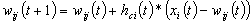 , (1)
, (1)где t обозначает время и hci (t) — ядро соседства вокруг нейрона C во время t, wij – вес связи входного нейрона i и выходного j, xi – i компонент входного вектора.
- Возврат к шагу 2
Ядро соседства — не увеличивающаяся функция времени и расстояния нейрона i от нейрона C. Оно определяет область влияния, которое входной вектор оказывает на SOM. Ядро сформировано из двух частей: функция соседства h(d,t) и функция шага обучения a(t):
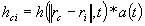 , (2)
, (2)где ri – координаты нейрона i в пространстве топологической карты.
Обычно, в качестве функции соседства используется функция Гаусса следующего вида:
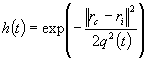 . (3)
. (3)Радиус соседства сначала берётся большой, а затем линейно уменьшается во время обучения.
Функция шага обучения — убывающая функция времени. В её качестве может быть использована линейная функция или функция, обратно пропорциональная времени.
Рекомендуется разбивать обучение на 2 фазы. В первой фазе (упорядочивания) используется относительно большое начальное значение шага обучения и радиуса соседства. Во второй фазе (настройки) и шаг обучения и радиус соседства малы с самого начала.
В пакетном варианте алгоритма обучения сети предъявляется сразу вся обучающая выборка, и только после этого происходит модификация весов с учётом влияния всех элементов выборки. Пакетный алгоритм сходится намного быстрее, чем последовательный алгоритм.
Качество обучения оценивается с помощью двух параметров. Ошибка подгонки описывает, как точно нейроны подогнаны под обучающую выборку. Она равна среднему расстоянию вектора из выборки до ближайшего к нему нейрона:
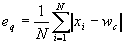 . (4)
. (4)Топологическая ошибка показывает, насколько хорошо пространство топологической карты описывает пространство входных векторов. Она вычисляется по следующей формуле:
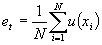 , (5)
, (5)где u(xi) равна 1, если два ближайших к вектору xi нейрона не являются соседями, и 0 в противном случае.
Если при обучении сети не использовать функцию соседства, то мы получим модель VQ (Vector Quantization). Она представляет собой нейросетевой вариант метода динамических ядер и также используется для кластеризации.
При визуализации результата обучения используется диаграмма попаданий (ДП) и U-матрица.
Для построения ДП вычисляется число ближайших примеров из выборки для каждого нейрона выходного слоя, после чего эти значения отображаются на топологической карте. ДП может быть построена как по всей выборке, так и только по элементам одного класса. Группировка элементов, при-
надлежащих к разным классам, в различных областях диаграммы попаданий говорит о возможности их классификации с помощью исходных данных.
U-матрица показывает расстояния между нейронами слоя топологической карты в пространстве входных признаков. На ней хорошо видны выделяющиеся кластеры.
Одно из возможных применений SOM — разведочный анализ данных. Сеть Кохонена может распознавать кластеры в данных, а также устанавливать близость классов. Таким образом, исследователь может улучшить свое понимание структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи классификации. Сети Кохонена можно использовать и в тех задачах классификации, где классы уже заданы, — тогда преимущество будет в том, что сеть сможет выявить сходство между различными классами.
- Методика проведения и результаты исследования
Для обучения нейросети была создана база данных о 150 пациентах. Перед использованием для обучения данные были нормированы. Использовалась SOM со следующими параметрами:
- Входной слой – 17 нейронов.
- Выходной слой – двумерная сетка 13? 6 нейронов, каждый нейрон (кроме крайних) имеет 6 соседей. Функция соседства – гауссиана.
- Алгоритм обучения – пакетный. Обучение состоит из двух фаз. Функция шага обучения – линейная функция времени.
В результате обучения получена сеть с топологической ошибкой et=0 и ошибкой подгонки eq=1.9563. ДП для всей выборки и U-матрица показаны на рисунках 1 и 2.
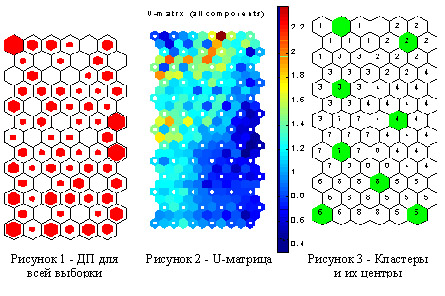
ДП для наиболее часто встречающихся диагнозов показаны на рисунках 3-5.
С помощью полученных визуальных данных на карте признаков были вручную выделены 8 центров предполагаемых кластеров. Затем была создана модель VQ с 8 нейронами в выходном слое, веса связей которых соответствовали выбранным центрам. Обучения VQ дало оптимальные центры кластеров. На рисунке 3 показаны полученные кластера и их центры на топологической карте. На рисунках 6-7 показаны графики изменения объема желудочного сока и кислотности, соответствующие центрам 1 и 2 кластеров.
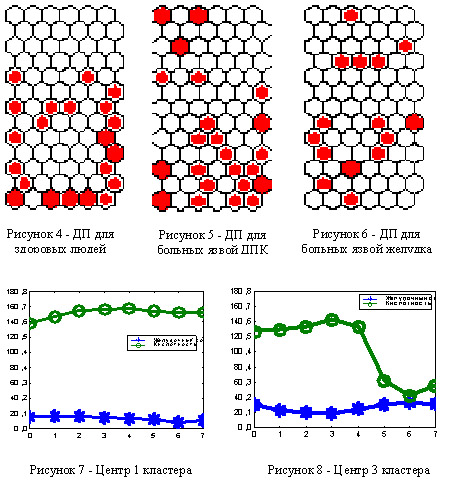
На U-матрице хорошо видно, что из всего массива данных сильно выделяются только 1, 2 и 3 кластеры. Это подтверждается графиками их центров.
Распределение больных с различным диагнозом по кластерам показано на таблице 1. Нельзя сказать, что анализы больных с одинаковым диагнозом принадлежат одному кластеру. Однако, по принадлежности анализа к кластеру можно делать некоторые выводы. Например, если анализ попал в 1 или 2 кластер, то он принадлежит больному человеку.
Следовательно, исходных данных недостаточно для того, чтобы поставить больному точный диагноз. С их помощью можно указать лишь круг наиболее вероятных болезней.
Таблица 1 — Распределение анализов больных с различным диагнозом
по кластерам
Диагноз
Кластер
1
2
3
4
5
6
7
8
Язва желудка
1
2
2
3
0
1
3
6
Язва ДПК
4
0
5
4
7
6
2
6
Гастрит
3
0
2
4
2
0
2
0
Желчекаменная болезнь
2
2
0
1
0
0
0
0
Хронический гастрит
2
0
1
3
0
0
1
1
Хронический колит
0
0
3
4
0
0
0
1
Калькулёзный холецистит
1
2
1
2
1
0
1
1
Хрон. кальк. холецистит
1
3
3
3
0
0
0
2
Холецистит
3
2
1
1
1
0
0
0
Здоров
0
0
2
10
8
5
2
1
Всего
18
11
20
35
19
13
13
20
6. Заключение
Для кластеризации анализов больных Курганской областной больницы были использованы нейросетевые модели Кохонена: SOM и VQ. В результате было получено графическое представление многомерного пространства анализов и произведёно их разбиение на кластеры. По итогам исследования можно сделать вывод, что имеющихся анализов не достаточно для постановки точного диагноза, что и понятно, но они в ряде случаев могут указать на наиболее вероятные заболевания. Главное, удалось классифицировать и найти типовые усредненные характеристики классов для данных анализов и их дальнейшего исследования специалистами.
Литература
- Sarle, W.S., ed. (1997), Neural Network FAQ, part 1 of 7 URL: ftp://ftp.sas.com/pub/neural/FAQ.html
- Johan Fredrik Markus Svensen, “GTM: The Generative Topographic Mapping”, Aston University 1998. Р. 28-33.
- Сайт “Нейроверстак”, http//www.neuralbench.ru/RUS/THEORYKOHONEN.HTM
Источник: http://www.kurgan-city.ru/conf1/simahin1.html , доступ 02.09.2008

Разработка и продвижение
Профессиональная разработка и продвижение сайтов и интернет магазинов.
Получите отличную поддержку
Отзывчивая и ответственная служба технической поддержки.
Быстрая работа сервера
Настраиваемый (responsible) дизайн способствует увеличению продаж.